SISTEMA DE ARQUIVOS NO LINUX: POR TRÁS DOS PANOS
Decidi fazer este post porque estou começando a estudar um pouco mais afundo algumas coisas no Linux, como o gerenciamento de memória, processos e sistemas de arquivos. Durante esse tempo de estudos, descobri e entendi alguns conceitos que ainda não estavam 100% claros para mim e gostaria de compartilhar com vocês.
O objetivo deste post é clarificar de uma forma simples, como está desenhada a arquitetura de sistemas de arquivos do Linux.
Linux Virtual File System
Antes de começar a falar de algum sistema de arquivos específico, o cara que faz toda a mágica acontecer é o Virtual File System, ou o chamado VFS.
O VFS é um sistema de arquivos implantado dentro do Kernel Linux e é usado por todos os sistemas de arquivos conhecidos, como por exemplo o EXT4, XFS, Btrfs e assim por diante…
A função do VFS é ser basicamente um framework para os outros sistemas de arquivos. Vendo por essa perspectiva, toda a lógica de leitura de arquivos e escrita é criada pelo VFS. Veja a imagem abaixo (kibada do site da IBM):
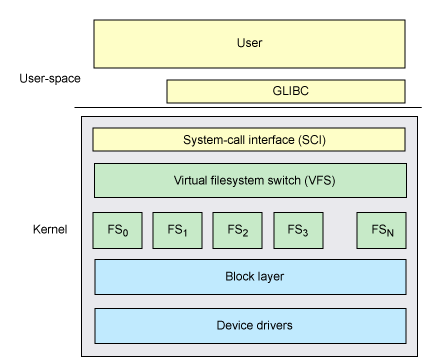
Perceba que o VFS está localizado justamente entre as system calls e os file systems a nível de bloco.
Talvez alguma vez você já tenha se perguntado… Com o Linux suporta tantos sistemas de arquivos assim? Como ser tão versátil? A resposta está em ter um framework único que traduz as instruções para os sistemas de arquivos.
1. Inode
Agora que você já tem uma ideia do que é o VFS, vamos falar de algumas funções implementadas por ele e que são usados pelos outros sistemas de arquivos?
Você já ouviu falar em Inode (index node)? Você pode dar uma olhada no post abaixo que eu fiz posteriormente:
Um Inode é uma estrutura de dados usada pelo VFS para organizar os arquivos dentro de um sistema de arquivos. Por isso que tanto o XFS e o EXT4 possuem índices de inodes (roda um “ls -i” para ver). O XFS e o EXT4 passam pela camada de abstração do VFS para ter contato com o userspace.
O Inode armazena metadados como:
- Permissões
- Owner
- Grupo
- Tamanho do arquivo
- Número de hardlinks para o arquivo
- Último acesso
- Última modificação
Além disso, ele armazena um apontamento para a localização no bloco do disco de onde o arquivo está localizado. Ah, já ia esquecendo… Tudo no Linux é tratado como um arquivo. Um diretório também tem um Inode e é tratado como um arquivo.
O ponto é que o diretório é um tipo especial de Inode que possui um apontamento para outro diretório lá dentro, por isso que ele consegue trabalhar em forma de árvore. Por exemplo, o diretório “/” seria um Inode com um apontamento para todos os diretórios dentro dele…
Se você quiser aprender um pouco mais sobre o código em C que implementa os Inodes, sugiro dar uma lida nos livros de arquitetura do Linux.
2. Directory Entry Cache
Como você já deve imaginar, encontrar milhares de Inodes no sistema nem sempre é uma tarefa fácil para o nosso querido Linux. Imagina em um servidor de arquivos que haverão milhares e milhares de arquivos…
Mas é aí que entra o famoso Cache! Também conhecido como “Dentry Cache” ou “DCache”. Se você acessou algum arquivo ou realizou algum tipo de busca que demorou um tempo, a próxima vez que rodar será bem mais rápida, pois o Linux usa esse recurso para agilizar a busca. Ah, o cache fica na RAM, por isso é tão rápido!
Na verdade, aqui temos que dividir em dois assuntos: O Dentry e o Cache. O Dentry mantém um link entre o Inode e o arquivo real. O Dentry Cache se encarrega de colocar no cache esses objetos do tipo dentry.
Em caso de uma busca (usando o find por exemplo), o que acontece é:
- Você busca por um diretório com um determinado nome.
- O sistema vai encontrar objetos do tipo “dentry” com o nome do diretório
- Se encontrado, vai retornar o Inode com os metadados do objeto, e consequentemente, a localização no bloco do disco
Agora você já tem uma breve ideia do Dentry, vamos falar especificamente de como o Cache funciona.
Aliás, sugiro dar uma olhada no artigo abaixo:
Mas vamos lá! Se liga nesse exemplo (como root):
# time find / -iname "*.ko"
Esse comando vai buscar todos os arquivos com a extensão .ko no “/” e medir o tempo de busca.
O resultado foi:
real 0m18,192s
user 0m1,082s
sys 0m2,364s
São 18s para rodar essa busca. Mas olha o tamanho do nosso Cache agora:
# free -h
total usada livre compart. buff/cache disponível
Mem.: 15Gi 3,4Gi 10Gi 499Mi 2,1Gi 11Gi
Swap: 1,9Gi 0B 1,9Gi
São 2.1GB armazenados no Cache. Ah, esse Cache é liberado se você precisar de RAM, fica tranquilo! Agora vou rodar o find de novo e vamos ver quanto tempo vai levar.
real 0m1,780s
user 0m0,771s
sys 0m0,892s
Agora levou apenas 2 segundos… Por que será? Porque o Linux vai colocando as coisas que você mais acessa no Cache.
Existe um parâmetro chamado de “drop_caches” que faz a limpeza de Cache. É interessante para fins de teste.
# echo 3 > /proc/sys/vm/drop_caches
Não se preocupa, não vai apagar teu sistema não. Faz em uma VM para testar aí! Depois de fazer isso, roda o mesmo comando, você vai ver que vai levar os 18s novamente…
Superblock
Como você já deve imaginar, o Linux se organiza em blocos, assim como o próprio disco (por isso chamado de block device). Mas como se organizar em meio a tantos milhões de blocos? Tendo um blocão-chefe, o superblock.
Esse superblock armazena informações extremamente críticas para o sistema de arquivos, e caso ele seja apagado, sérios problemas podem acontecer. Por isso que o próprio sistema de encarrega de distribuir cópias de redundância desse superblock no disco, assim se ele for corrompido, dá para fazer o apontamento para algum outro.
Veja algumas informações armazenadas nele:
- O disco físico onde ele está localizado
- Tamanho dos blocos
- Tamanho máximo de um arquivo
- Tipo do sistema de arquivos
- Operações suportadas
- Magic Number (identifica qual é o FS)
- Apontamento para o diretório root “/”
Entende a importância dele para o sistema? Por isso que quando o sistema corrompe, geralmente apontando um outro endereço de superblock para o fsck pode resolver o problema.
O que acontece quando criamos um arquivo?
Vamos entender na prática como funciona isso:
- Você cria um arquivo com o comando “echo” por exemplo, em userspace, ou seja, você não está em “kernelspace” para ter acesso a coisas de baixo nível como escrever no sistema de arquivos. Então, o que acontece?
- Seu sistema usa uma biblioteca chamada de “libc” ou “glibc” que tem todas as system calls dentro dele. Todos os utilitários acabam utilizando system calls para tomar uma ação. Essas systems calls estão em userspace e fazem contato com o kernelspace.
- O sistema vai usar a system call de “write()” para escrever no file system, mas espera, não é no file system como XFS. Na verdade, ele vai contatar o VFS!
- O VFS por sua vez vai traduzir isso para o XFS ou qualquer outro file system. É uma camada de tradução que não importa o file system por baixo, sempre será a mesma chamada da perspectiva de usuário. Muito legal, não acham?
Vamos ver isso em mais detalhes usando o comando “strace” para ver as chamadas.
$ strace -e trace=open,write echo "oi" > oi.txt
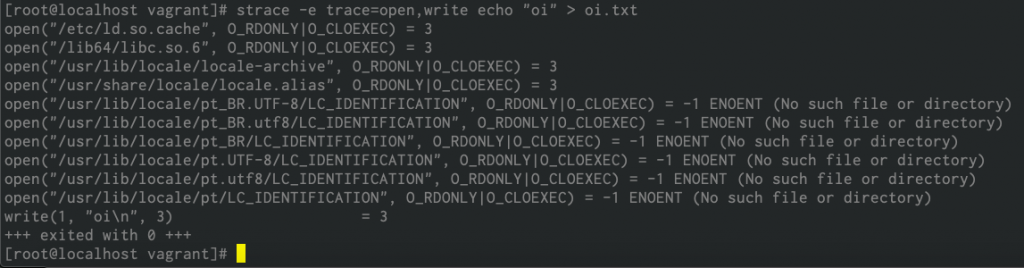
Veja que há uma chamada para a libc e posteriormente uma chamada para o método write que vai escrever no VFS.
A mesma coisa vai acontecer com o EXT4 ou outros sistemas de arquivos.
Conclusão
O VFS é uma camada de abstração o que permite escolhermos e utilizarmos o sistema de arquivos que queremos, já que todos serão abstraídos pelo VFS. Sugiro seguir seus estudos pesquisando um pouco sobre superblocks e dentry cache no VFS!
Bom, espero que você tenha gostado dessa dica e que você realmente usufrua dela! Sei que é algo complexo e com certeza vai exigir mais estudos da sua parte. Boa sorte!
Me siga no Instagram onde eu faço conteúdos da minha rotina diária.
Participe dos nossos grupos no Telegram e Facebook! 🙂
Se tiver alguma dúvida ou sugestão de conteúdo, por favor, comente!